DCL
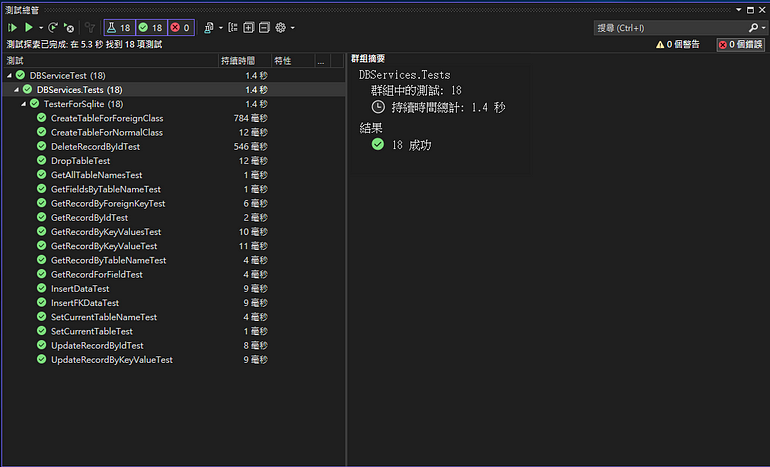
這邊所說的DCL與一般定義不同,非CRUD類的都會放在這兒。取回所有資料表
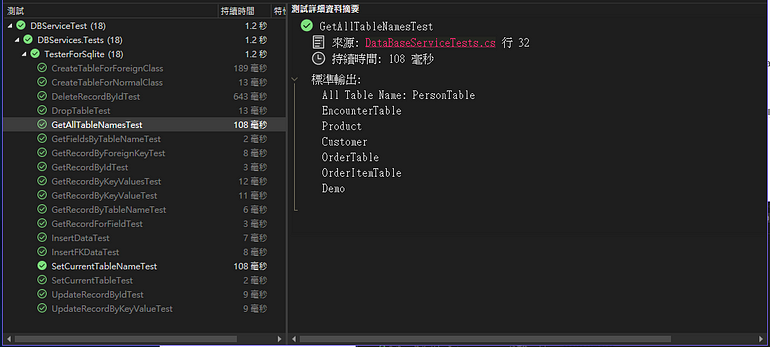
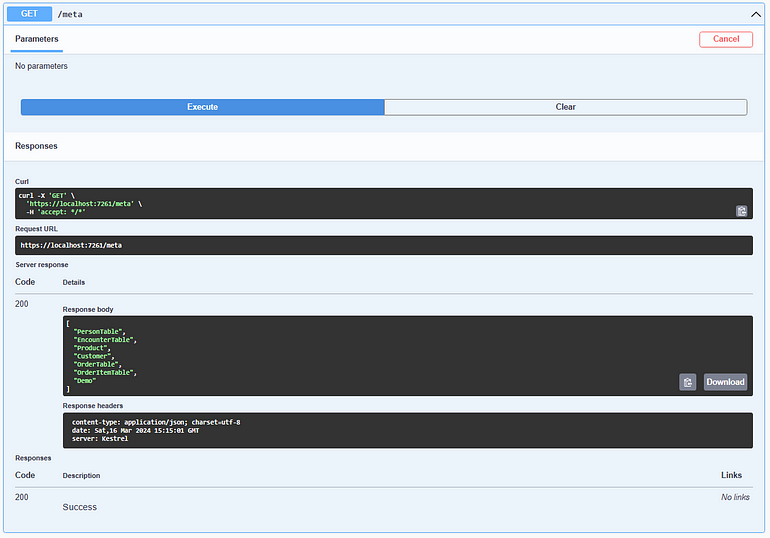
利用GetAllTableNames()來取回目前資料庫中所有資料表(含view,不要含view則參數設false)。
[]
public virtual void GetAllTableNamesTest()
{
string[]? allTableName = _db.GetAllTableNames();
Assert.IsNotNull(allTableName);
Assert.IsTrue(allTableName.Length > 0);
Console.WriteLine($"All Table Name: {string.Join("\r\n", allTableName)}");
}
測試結果:
使用SetCurrentTableName(string tableName)可透過字串設定目標資料表。GetCurrentTableName()可以確認目前是否有設定好目標資料表。
public virtual void GetAllTableNamesTest()
{
string[]? allTableName = _db.GetAllTableNames();
Assert.IsNotNull(allTableName);
Assert.IsTrue(allTableName.Length > 0);
Console.WriteLine($"All Table Name: {string.Join("\r\n", allTableName)}");
}
測試結果:
設定資料表
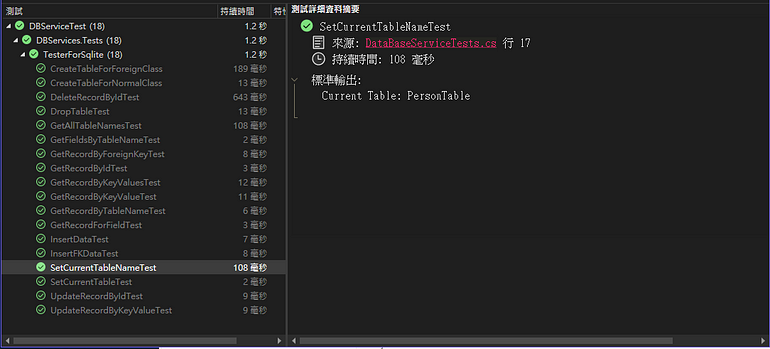
這個目的是告訴DbService 現在要針對那個資料表進行處理。其實,所有的函數都可以接受資料表名稱參數,只是設定後,就可以不用輸入。使用SetCurrentTableName(string tableName)可透過字串設定目標資料表。GetCurrentTableName()可以確認目前是否有設定好目標資料表。
[]
public virtual void SetCurrentTableNameTest()
{
_db.SetCurrentTableName("PersonTable");
Assert.AreEqual("PersonTable", _db.GetCurrentTableName());
Console.WriteLine($"Current Table: {_db.GetCurrentTableName()}");
}
測試結果:
使用SetCurrentTable<T>()則可在已知Modle下,設定目標資料表。
public virtual void SetCurrentTableNameTest()
{
_db.SetCurrentTableName("PersonTable");
Assert.AreEqual("PersonTable", _db.GetCurrentTableName());
Console.WriteLine($"Current Table: {_db.GetCurrentTableName()}");
}
測試結果:
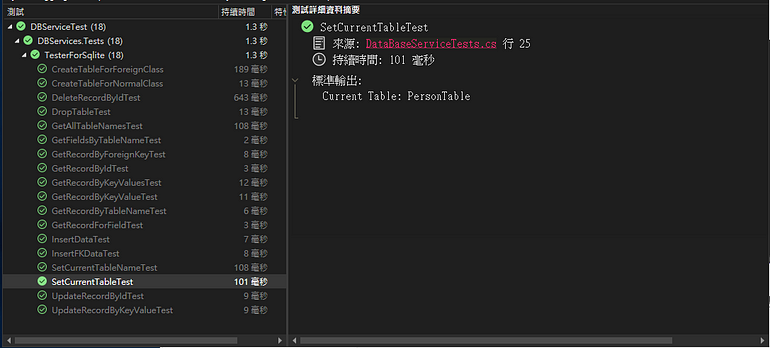
使用SetCurrentTable<T>()則可在已知Modle下,設定目標資料表。
[]
public virtual void SetCurrentTableTest()
{
_db.SetCurrentTable<PersonTable>();
Assert.AreEqual("PersonTable", _db.GetCurrentTableName());
Console.WriteLine($"Current Table: {_db.GetCurrentTableName()}");
}
測試結果:
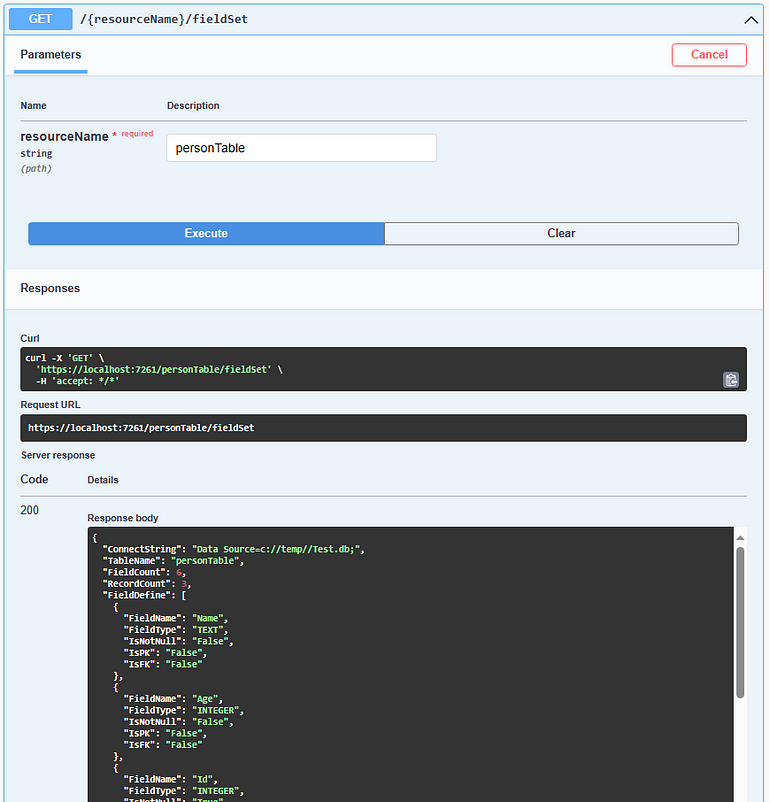
使用GetFieldsByTableName(string tableName)可以取回此資料表的所有資訊。回傳型態是IEnumerable<FieldBaseModel>。FieldBaseModel的結構後續再討論。
public virtual void SetCurrentTableTest()
{
_db.SetCurrentTable<PersonTable>();
Assert.AreEqual("PersonTable", _db.GetCurrentTableName());
Console.WriteLine($"Current Table: {_db.GetCurrentTableName()}");
}
測試結果:
取回資料表欄位定義
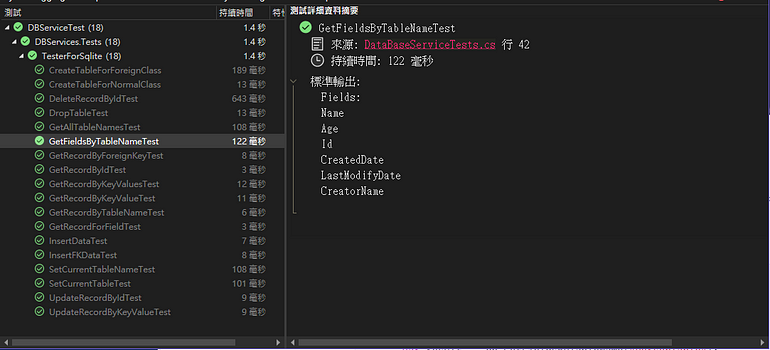
使用GetFieldsByTableName(string tableName)可以取回此資料表的所有資訊。回傳型態是IEnumerable<FieldBaseModel>。FieldBaseModel的結構後續再討論。
[]
public virtual void GetFieldsByTableNameTest()
{
var result = _db.GetFieldsByTableName("PersonTable");
Assert.IsNotNull(result);
Assert.IsTrue(result.Any());
var nameList = from item in result
select item.FieldName;
Console.WriteLine($"Fields:\r\n{string.Join("\r\n", nameList)}");
}
測試結果:
public virtual void GetFieldsByTableNameTest()
{
var result = _db.GetFieldsByTableName("PersonTable");
Assert.IsNotNull(result);
Assert.IsTrue(result.Any());
var nameList = from item in result
select item.FieldName;
Console.WriteLine($"Fields:\r\n{string.Join("\r\n", nameList)}");
}
測試結果:



 個水準下,各別進行了
個水準下,各別進行了 次的隨機抽樣數。用一個式子就把它表達出來。所以,不要開始被這些式子給嚇到了。
次的隨機抽樣數。用一個式子就把它表達出來。所以,不要開始被這些式子給嚇到了。%5E2&container=blogger&gadget=a&rewriteMime=image%2F*)




